
It shouldn't be too much of a surprise that the Internet has evolved into a force strong enough to reflect the greatest hopes and fears of those who use it. After all, it was designed to withstand nuclear war, not just the puny huffs and puffs of politicians and religious fanatics.Denise Caruso
The 'Net is a waste of time, and that's exactly what's right about it.William Gibson
Looking at the proliferation of personal web pages on the net, it looks like very soon everyone on earth will have 15 Megabytes of fame.M.G. Siriam
The Internet is a vast network of computers, connecting people from across the world. Through the Internet, a person in Indiana can communicate freely with a person in India, scientists at different universities can share computing power, and researchers can access libraries worth of information regardless of physical location. The World Wide Web provides a simple, intuitive interface for users to share and access information, and has even become an essential medium for advertising and commerce.
Chapter 1 provided an overview of the Internet and the Web from a user's perspective. It emphasized the differences between the Internet and the Web, noting that the Internet is hardware (computers, cable, wires, …) while the Web is software (documents, images, sound clips, …) that is stored and accessed over the Internet. This chapter provides more details as to how the Internet and Web developed and how they work.
|
|

|
The original intent of the ARPANet was to connect military installations and universities that participated in government projects. By 1981, more than 200 computers were connected to the ARPANet, allowing researchers to share information and computer resources. Driven by the popularity of network applications such as electronic mail, newsgroups, and remote computer logins, the number of computers on the Internet exceeded 10,000 by 1987. Looking toward future growth, the National Science Foundation (NSF) funded high-speed transmission lines that would form the backbone of the expanding network. The term "Internet" was coined in recognition of the similarities between the computer network and the interstate highway system. The backbone connections were analogous to interstate highways, providing fast communications between major destinations. Connected to the backbone were transmission lines with slower, more limited capabilities, connecting secondary destinations analogous to state highways. Additional levels would be required before reaching individual computers, similar to the city and neighborhood roads required to reach individual houses. Control of the Internet was transferred to the private sector in the early 1990's. The physical components of the Internet are now managed by commercial firms such as MCI WorldCom, which built the very high-speed Backbone Network System (vBNS) in 1995 to replace existing backbone connections. The workings of the Internet are managed by a non-profit organization, the Internet Society, whose committees rely largely on volunteers to design the technology and protocols that define the Internet.
The table below documents the growth of the Internet over the past two decades, as estimated by the Internet Software Consortium. These numbers indicate exponential growth, with the size of the Internet doubling every 1-2 years. An interesting consequence of exponential growth is that at any point in time, roughly half of the computers on the Internet were added within the last 1-2 years. Of course, exponential growth cannot continue indefinitely. To date, however, technological advances have been able to accommodate increasing demands and no immediate end to growth is foreseen.
| Year | Computers on the Internet |
|---|---|
| 2002 | 162,128,493 |
| 2000 | 93,047,785 |
| 1998 | 36,739,000 |
| 1996 | 12,881,000 |
| 1994 | 3,212,000 |
| 1992 | 992,000 |
| 1990 | 313,000 |
| 1988 | 56,000 |
| 1986 | 5,089 |
| 1984 | 1,024 |
| 1982 | 235 |

|
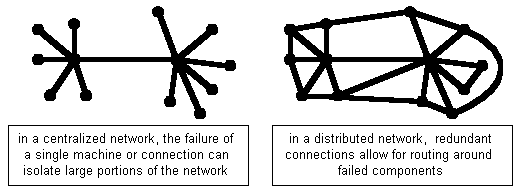
The other idea proposed by Baran (among others) that was central to the ARPANet architecture was that of packet-switching. In a packet-switching network, messages to be sent over the network are first broken into small pieces known as packets, and those packets are then sent independently to their final destination. There are three main advantages to transmitting messages in this way. First, it tends to make more effective use of the connections. Data communications tend to mostly involve short transmission bursts. If large messages were able to monopolize a connection, many smaller messages might be forced to wait. As a real life example of this effect, think of a line at a busy pay phone. If the person currently on the phone has a long conversation, then everyone else in line, even those who only have to make short calls, must wait. If phone calls were limited in length, say 3 minutes per call, then each person in line would be guaranteed a turn in a reasonable amount of time. Similarly, limiting the size of messages transmitted over the network allows many users to share the connections. The second advantage of packet-switching is related to the distributed nature of the network. Since there are numerous paths that a message might take in reaching its destination, it is advantageous to be able to send parts of the message along different routes, say if a portion of the network fails or becomes overloaded during transmission. The third advantage is that packet-switching improves reliability. If a message is broken into packets and the packets are transmitted independently, then there is a high likelihood that at least part of the message will arrive at its destination, even allowing for some failures within the network. If the recipient receives only part of the message, they can acknowledge its receipt and request retransmission from the sender.
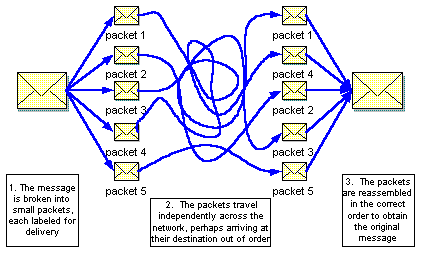
While the terms distributed and packet-switching describe the architecture of the Internet, they do not address how computers connected to the Internet are able to communicate effectively. After all, people from around the world speak different languages and have different customs. If the average American can't speak or understand Russian (and vice versa), how can we expect a computer in Nebraska to communicate with a computer in Moscow? The solution to this problem is to agree upon protocols, sets of rules that describe how communication is to take place. As a real-world example, consider the postal system (jokingly referred to as snail-mail by some in the electronic community). If every state or country used its own system for labeling mail for delivery, sending a letter would be an onerous if not impossible task. Fortunately, protocols have been established for uniquely specifying addresses, including zip codes or country codes that allow letters to be easily sent across the country or across the world. Similarly, protocols were established for the Internet that define how computers are to be addressed and the form by which messages must be labeled for delivery
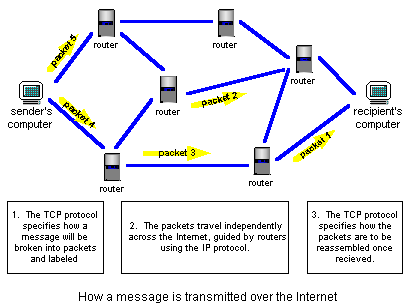
Similar to the manner in which houses are assigned addresses to uniquely identify them, computers on the Internet are assigned unique addresses known as IP addresses. An IP address is a number, usually written as a dotted sequence such as 147.134.2.20. When a new computer is to be connected to the Internet, it must be assigned an IP address through a local organization or Internet Service Provider (ISP). Once the computer has its IP address and is physically connected to the network, it can send and receive messages and access other Internet services. The manner in which messages are sent and received over the Internet is determined by a pair of protocols called the Transmission Control Protocol (TCP) and Internet Protocol (IP). TCP is concerned with the way that messages are broken down into packets, then reassembled by the recipient. IP is concerned with labeling the packets for delivery and controlling the path that they take to their destination. The combination of these two protocols, written as TCP/IP, is often referred to as the language of the Internet. Any computer that is able to "speak" the language defined by TCP/IP will be able to communicate with any other computer on the Internet.
When a person wants to send a message over the Internet, software using the rules spelled out by TCP will break that message into packets (no bigger than 1,500 characters each) and label the packets as to their sequence (e.g., packet 2 of 5). Software following rules spelled out by IP will label those packets with routing information, including the IP addresses of the source and destination computers. Once labeled, the packets are sent independently over the Internet. Special purpose machines called routers receive the packets, access the routing information, and pass them on towards their destination. The routers utilize various information sources, including statistics on traffic patterns, to determine the best direction for each packet to follow. As an analogy, consider driving a car to a familiar destination. You most likely have a standard route that you take, but may adjust that route if you see heavy traffic ahead or know of road closings due to construction. In a similar way, routers are able to adjust to congestion or machine failures and send each individual packet in the best direction at that time. When the packets arrive at their destination, possibly out of order due to the various routes taken, TCP software running on the recipient's computer reassembles the packets to obtain the original message.
From a user's perspective, remembering the digits that make up IP addresses can be tedious and error-prone. Mistyping only one digit in an IP address might mistakenly identify a computer half way around the world. Fortunately, the Internet allows for individual machines to be assigned names that can be used in place of the IP address. For example, the computer with IP address 147.134.2.20 can be referred to by the name bluejay.creighton.edu. Such names, commonly referred to as domain names, are hierarchical in nature to make them easier to remember. The leftmost part of the name specifies the name of the machine, with subsequent parts specifying the organization and possibly sub-organizations that computer belongs to. The rightmost part of the domain name is known as the top-level domain, which identifies the type of organization involved. For example, the computer bluejay.creighton.edu is named bluejay and belongs to Creighton University, which is an educational institution. Similarly, www.sales.acme.com is a computer named www, belonging to the sales department of a fictional Acme Corporation, which is a commercial business.
Examples of common top-level domains are listed in the table below. In addition, countries have their own top-level domain, such as ca (Canada), uk (United Kingdom), br (Brazil) and in (India).
| edu | U.S. educational institutions |
| com | commercial organization |
| org | non-profit organizations |
| mil | U.S. military |
| gov | U.S. government |
| net | network providers & businesses |
While domain names are easier for users to remember, any communication that is to take place over the Internet requires the IP address of the source and destination computers. Mappings between domain names and IP addresses are stored on special-purpose computers called domain name servers (DNS). When a message is to be sent to a destination such as bluejay.creighton.edu, a request is first sent to a domain name server to map the domain name to an IP address. The domain name server looks up the domain name in a table and sends the IP address (here, 147.134.2.20) back to the sender's computer so that the message can be sent to the correct destination. If a particular domain name server does not have the requested domain name stored locally, it forwards that request to another domain name server on the Internet until the correct mapping is found.

|
The idea of linking documents together so that they could be accessed easily and in flexible ways was not new to Berners-Lee. The idea of hypertext, documents with cross-linked and interlinked text and media, has been around for centuries in the form of books with alternate story lines, e.g., "If the knight defeats the dragon, continue at page 37. If not, continue at page 44." In 1945, Presidential science advisor Vannevar Bush outlined ideas for a machine that would store textual and graphical information in such a way that any piece of information could be arbitrarily linked to any other piece. Small-scale hypertext systems were developed for computers starting in the 1960's, culminating in the popular HyperCard system that shipped with Apple Macintosh computers in the late 1980's. Berners-Lee's innovation was in combining the key ideas of hypertext with the distributed nature of the Internet. His design for the Web relied on two different types of software, running on computers over the Internet. A Web server is a computer that stores documents and "serves" them to other computers that want access. A Web browser is a piece of software that runs on and individual's computer and allows them to request and view the documents stored on servers. A person running a Web browser could access and jump between documents, regardless of the location of the servers storing those documents.

|
The table below documents the growth of the World Wide Web over the past decade, as estimated by the Netcraft Web Server Survey. It is interesting to note the dramatic increases in the size of the Web following advances in browser technology: Mosaic (1993), Netscape (1995), and Internet Explorer (1996). According to the latest estimates, roughly 1 out of every 5 computers on the Internet (20.4%) acts as a Web server. Of course, each Web server may store a large number of pages, and so the size of the Web in terms of pages is even more impressive. In 2002, the Google search engine (google.com) claimed to have more than 3 billion Web pages indexed, and other sources estimate as many as 5 billion pages and growing.
| Year | Computers on the Internet | Web Servers on the Internet |
|---|---|---|
| 2002 | 162,128,493 | 33,082,657 |
| 2000 | 93,047,785 | 18,169,498 |
| 1998 | 36,739,000 | 4,279,000 |
| 1996 | 12,881,000 | 300,000 |
| 1994 | 3,212,000 | 3,000 |
| 1992 | 992,000 | 50 |
The future development of the Web is now guided by a non-profit organization called the World-Wide Web Consortium (W3C), which produces new standards and oversees the design of new Web-based technologies. As part of the Internet Society, the W3C relies mainly on volunteer labor from technically-qualified and interested individuals.
As was the case with Internet communications, the World Wide Web relies on protocols to ensure that Web pages are accessible and viewable by any computer. As we saw in Chapters 1 and 2, the content of Web pages is defined using HTML, the HyperText Markup Language. By placing tags within a text document, the content of the page takes on special meaning. Part of the job of a Web browser is to read those tags and format the page accordingly. For example, when a browser encounters text enclosed in <b></b> tags, it interprets those tags as specifying bold text and displays the characters in a darker font.
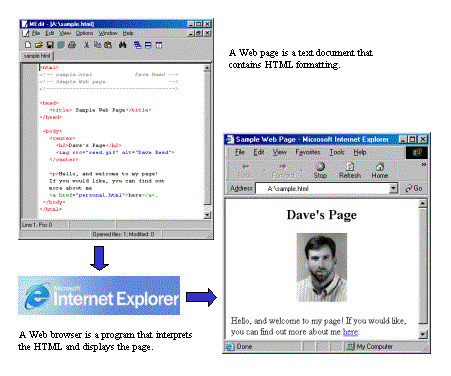
HTML is an evolving standard, with new features proposed and adopted as technology and user needs change. The current standard for HTML, as defined by the World Wide Web Consortium, is known as XHTML 1.0, recognizing its connections to the more general hypertext language XML. Web browsers work because they all understand and follow the HTML standard. While subtle differences may occur between browsers, all Web browsers understand the same basic set of tags and display the resulting text similarly. Thus, an author may place an HTML document on a Web server and be assured that it will be viewable by users regardless of their machine or browser software.
To a person "surfing" the Web, the process of locating, accessing, and displaying Web pages is transparent. When the person requests a particular page, either by entering its location into the Address box of the browser or else clicking on a link in an existing page, the new page is displayed in the browser window as if by magic. In reality, complex communications are taking place between the computer running the browser and the appropriate Web server. When the person requests the page, the browser must first identify the Web server where that page is stored. Recall from Chapter 1 that the Web address or URL for a page includes the name of the server as well as the document name. Once the server name has been extracted from the URL, the browser sends a message to that server over the Internet to request the page (following the steps described above for Internet communications). The Web server receives the request, locates the page within its directories, and sends the text of that page back in a message. When that message is received, the browser interprets the HTML formatting information embedded in the page and displays it appropriately in the browser window. The protocol that determines how the messages between the browser and server are formatted is known as the HyperText Transfer Protocol (HTTP).
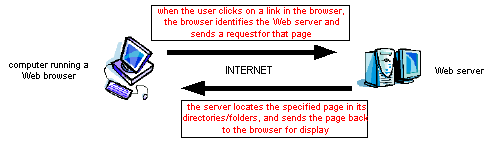
It is interesting to note that accessing a single page might involve several rounds of communication between the browser and server. If the Web page contains embedded elements, such as images or sound clips, the browser will not recognize this until it begins displaying the page. When the browser interprets the HTML tag that specifies the embedded element, it will then send a separate request to the server for the item. Thus, a page containing 10 images will requires 11 interactions between the browser and server, one for the page itself and one for each of the 10 images. To avoid redundant and excessive downloading, most browsers utilize a technique called caching. When a page or image is first downloaded, it is stored in a temporary directory on the user's computer. The next time that page or image is requested, the browser first checks to see if it has a copy stored locally in the cache, and if so, whether it is up-to-date (by contacting the server and asking how recently the page was changed). If an up-to-date copy is stored locally, then the browser can display this copy instead of taking the time to download the original. Note that it is still necessary for the browser to contact the Web server, since the document on the server might have changed since it was last cached. However, caching can still save the time and effort of downloading a redundant copy.
Answers to be emailed to your instructor by Thursday at 9 a.m.
Berners-Lee, Tim, Mark Fischetti (contributor) and Michael L. Derouzos. "Weaving the Web: The Original Design and Ultimate Destiny of the World Wide Web", HarperBusiness, 2000.
Bush, Vannevar. "As We May Think." Atlantic Monthly, July 1945.
http://www.theatlantic.com/unbound/flashbks/computer/bushf.htm
Comer, Douglas E. "The Internet Book: Everything you need to know about computer networking and how the Internet works, 3rd Edition", Prentice Hall, 2000.
Deitel, H.M, P.J Deitel, and T.R. Nieto. "Internet and World Wide Web: How to Program", Prentice Hall, 2000.
Griffin, Scott. "Internet Pioneers", December 2000.
http://www.ibiblio.org/pioneers/index.html
Hafner, Katie and Matthew Lyon. "Where Wizards Stay Up Late: The Origins of the Internet", Touchstone Books, 1998.
Leiner, Barry M., Vinton G. Cerf, David D. Clark, Robert E. Kahn, Leonard
Kleinrock, Daniel C. Lynch, Jon Postel, Larry G. Roberts, and Stephen Wolf.
"A Brief History of the Internet, version 3.31", August 2000.
http://www.isoc.org/internet/history/brief.shtml